
Python入门
python前言
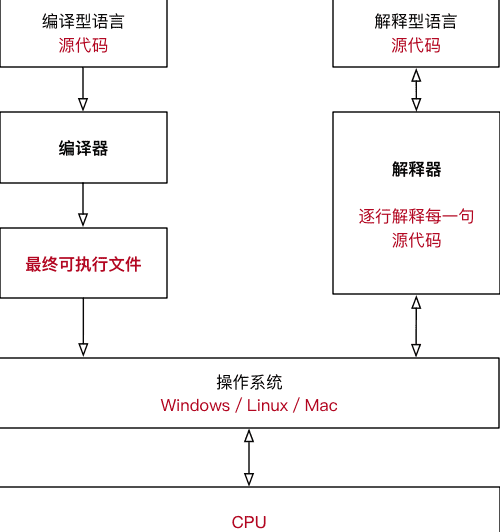
解释器
计算机不能直接理解任何除机器语言以外的语言,必须要把程序语言翻译成机器语言,计算机才能执行程序。
编译器:将其他语言翻译成机器语言的工具(编译器翻译方式:编译,解释)
两种方式的区别在于翻译时间点的不同。当编译器以解释方式运行的时候,也称之为解释器
-
编译型语言:程序执行之前需要有一个专门的编译过程,把程序编译成为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。
-
解释型语言:解释型语言编写的程序不进行预先编译,以文本方式存储程序代码,会将代码一句一句直接运行。在发布程序时,看起来省了道编译工序,但是在运行程序的时候,必须先解释再运行
-
速度:编译比解释型快
python特点
- 完全面向对象的语言
- 拥有一个强大的标准库
- 有大量的第三方模块
面向对象的思维方式
- 面向对象 是一种 思维方式,也是一门 程序设计技术
- 要解决一个问题前,首先考虑 由谁 来做,怎么做事情是 谁 的职责,最后把事情做好就行!对象 就是 谁
- 要解决复杂的问题,就可以找多个不同的对象,各司其职,共同实现,最终完成需求
- 先找一个可以完成功能的对象,并且使用对象所提供的能力来解决问题
python优缺点
优点
-
简单、易学
-
免费、开源
-
面向对象
-
丰富的库
-
可扩展性
如果需要一段关键代码运行得更快或者希望某些算法不公开,可以把这部分程序用
C或C++编写,然后在Python程序中使用它们
缺点
- 运行速度差一点
- 国内市场较小
- 中文资料匮乏
执行 python 程序的三种方式
- 解释器 —
python/python3 - 交互式 —
ipython - 集成开发环境 —
Pycharm
注:文件扩展名通常是 .py
python 的运行方式
Python 的解释器
# 使用 python 2.x 解释器
$ python xxx.py
# 使用 ptyhon 3.x 解释器
$ python3 xxx.pypython基础知识
注释
- 单行注释:以
#开头,后面加一个空格 - 多行注释:用一对连续的
三个引号即可(单,双引号均可)
# 这是一条注释
'''
这是
多行
注释
'''行与缩进
- python 与其他语言明显的区别是没有大括号,而是用缩进表示代码块
- 需要注意的是每行代码语句不需要以
;结尾(学过C语言的注意一下) - 注意:Python字符串不是通过
NUL(‘\0’)来结束,其字符串值只包含所定义的内容
变量的输入
- 在 Python 中可以使用
input函数从键盘等待用户输入 - 用户输入的任何内容 Python 都认为是一个字符串
# 语法
s = input("请输入:")
print("你输入了:"+s)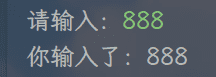
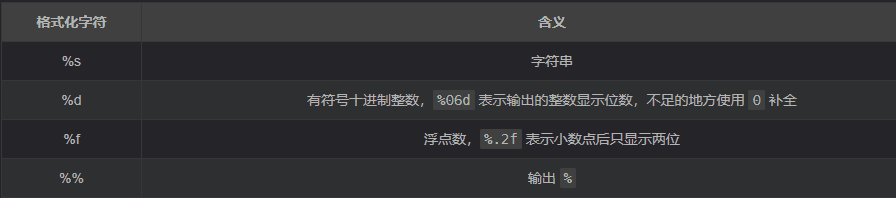
变量的格式化输出
%被称为格式化操作符,专门用于处理字符串中的格式- 包含
%的字符串,被称为格式化字串符 %和不同的字符连用,不同类型的数据需要使用不同的格式化字符
# 语法
a1 = "1"
a2 = "2"
num1 = 3.14
num2 = 12
num3 = 3
print("%s+%s=3" % (a1, a2)) # 1+2=3
print("%s==1" % a1) # 1==1
print("%s!=%f" % (a1, num1)) # 1!=3.140000
print("%d*%d" % (num2, num3)) # 12*3变量的命名规则
注意 Python 中的 标识符 是 区分大小写的
-
在定义变量时,为了保证代码格式,
=的左右应该各保留一个空格 -
在
Python中,如果 变量名 需要由 二个 或 多个单词 组成时,可以按照以下方式命名:① 每个单词都使用小写字母
② 小驼峰式命名法(第一个单词以小写字母开始,后续单词的首字母大写)
③ 大驼峰式命名法(每一个单词的首字母都采用大写字母)
变量的进阶
-
变量和数据 都是保存在 内存 中的
-
在
Python中 函数 的 参数传递 以及 返回值 都是靠 引用 传递的 -
引用的概念:
① 变量 和 数据 是分开存储的
② 数据 保存在内存中的一个位置
③ 变量 中保存着数据在内存中的地址
④ 变量 中 记录数据的地址,即 引用
⑤ 使用
id()函数查看变量中保存数据所在的 内存地址
注意:若变量已被定义,当给一个变量赋值的时候,本质上是 修改了数据的引用
① 变量 不再 对之前的数据引用
② 变量 改为 对新赋值的数据引用
- 在
Python中,函数的 实参/返回值 都是是靠 引用 来传递来的
可变和不可变类型
-
不可变类型,内存中的数据不允许被修改:
① 数字类型
int,bool,float,complex,long(2.x)② 字符串
str③ 元组
tuple -
可变类型,内存中的数据可以被修改:
① 列表
list② 字典
dict
注意:字典的 key 只能使用不可变类型的数据
可变类型的数据变化,是通过 方法 来实现的
若给一个可变类型的变量,赋值了一个新的数据,引用会修改
- 变量 不再 对之前的数据引用
- 变量 改为 对新赋值的数据引用
哈希(hash)
Python中内置有一个名字叫做hash(o)的函数,接收一个 不可变类型 的数据作为 参数,返回 结果是一个 整数哈希是一种 算法,其作用就是提取数据的 特征码(指纹)
① 相同的内容 得到 相同的结果
② 不同的内容 得到 不同的结果- 在
Python中,设置字典的 键值对 时,会首先对key进行hash已决定如何在内存中保存字典的数据,以方便 后续 对字典的操作:增、删、改、查 key必须是不可变类型数据value可以是任意类型的数据
局部变量和全局变量
- 不同的函数,可以定义相同的名字的局部变量,但是 彼此之间 不会产生影响,局部变量在函数执行时才会被创建,函数执行结束后,局部变量会被系统回收
注意:函数执行时,需要处理变量时 会:
① 首先 查找 函数内部 是否存在 指定名称 的局部变量,如果有,直接使用
② 若没有,查找 函数外部 是否存在 指定名称 的全局变量,如果有,直接使用
③ 若还没有,程序报错!
-
函数不能直接修改
全局变量的引用① 全局变量 是在 函数外部定义 的变量(没有定义在某一个函数内),所有函数
内部都可以使用这个变量② 在函数内部,可以 通过全局变量的引用获取对应的数据
③ 但是,不允许直接修改全局变量的引用 —— 使用赋值语句修改全局变量的值
注意:注:只是在函数内部定义了一个局部变量而已,只是变量名相同 —— 在函数内部不能直接修改全局变量的值
- 若在函数中需要修改全局变量,需要使用
global进行声明 - 全局变量定义的位置:定义在其他函数的上方
global需要在函数内部声明
def fun():
global a
a = 99
a = 4
b = 6
fun()
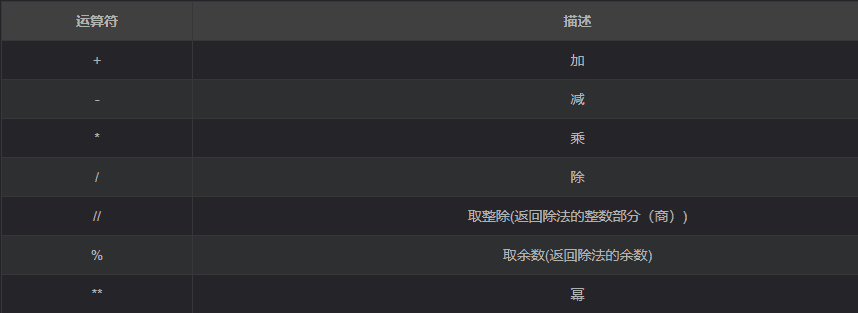
print(a) # 99算术运算符
- 在 Python 中
*还可以用于字符串,结果是字符串重复指定次数的结果 - Python 2.x 中判断 不等于 还可以使用
<>运算符;!=在 Python 2.x 中同样可以用来判断 不等于
逻辑运算符

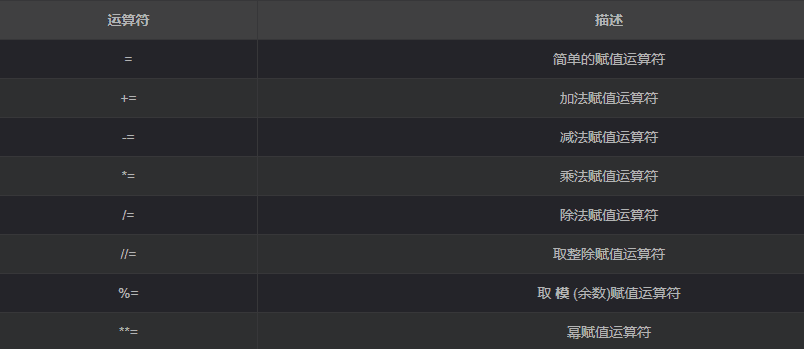
赋值运算符
- 注:赋值运算符中间不能使用空格
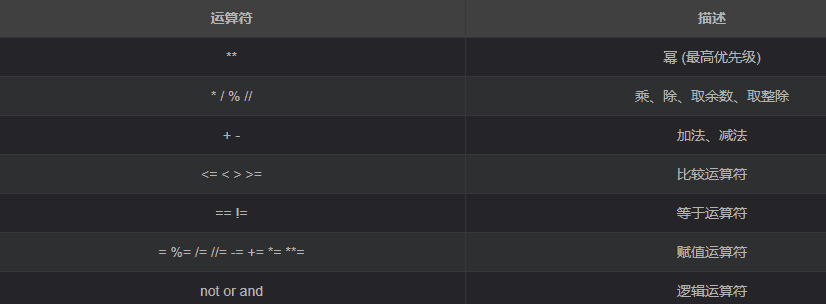
运算符的优先级
sort 与 sorted 区别
sort是应用在 list 上的方法,sorted可以对所有可迭代的对象进行排序操作- list 的
sort方法返回的是对已经存在的列表进行操作,无返回值 - 内建函数
sorted方法返回的是一个新的 list,而不是在原来的基础上进行的操作
print 函数
- 在默认情况下,
print函数输出内容之后,会自动在内容末尾增加换行 - 如果不希望末尾增加换行,可以在
print函数输出内容的后面增加, end="" - 其中
""中间可以指定print函数输出内容之后,继续希望显示的内容 - 语法格式如下:
# 不会换行
print("123", end="")
# 单纯换行
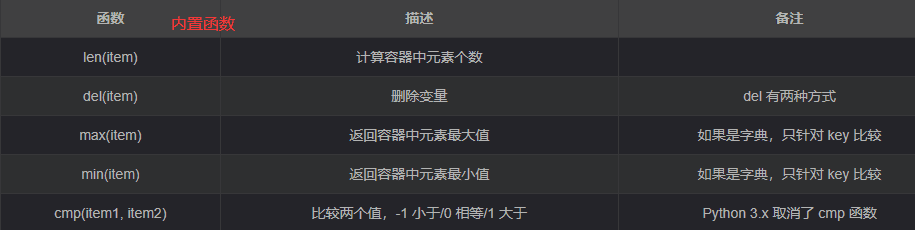
print("")公共方法

- 运算符
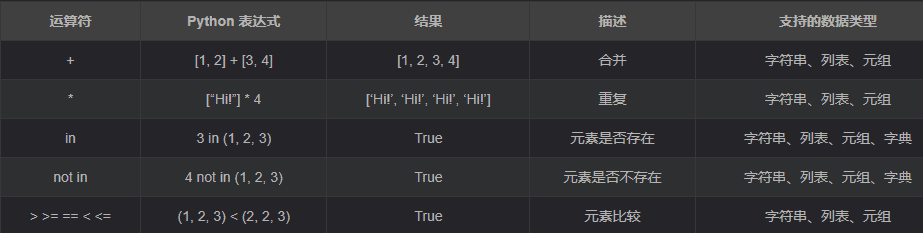
- 成员运算符
① in 在对 字典 操作时,判断的是 字典的键
② in 和 not in 被称为 成员运算符

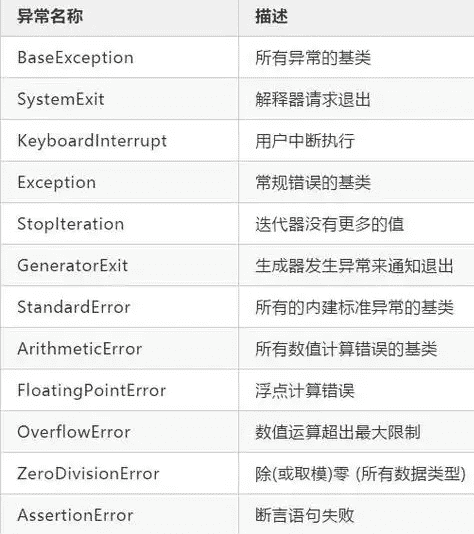
常见关键字
Python一共33个关键字
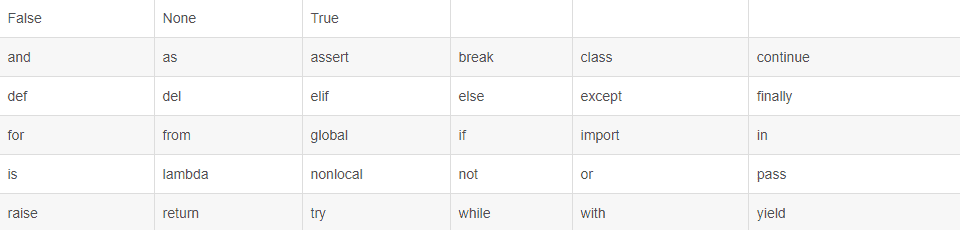
常用的关键字用法与注意事项
- del
① 使用 del 关键字(delete) 同样可以删除列表中元素
② del 关键字本质上是用来 将一个变量从内存中删除的
③ 如果使用 del 关键字将变量从内存中删除,后续的代码就不能再使用这个变量了
del list1[1]- as
① with...as... ,主要用于文件的读写操作,省去关闭文件的麻烦
② 导入模块起别名 ,对导入的模块进行重命名,或者导入函数对函数重命名
③ 将捕获到的异常对象赋值给 except
数据类型
- Python 中数据类型可以分为 数字型 和 非数字型
- 数字型
整型(int),浮点型(float),布尔型(bool),复数型(complex)
- 非数字型
字符串,列表,元组,字典
- 在 Python 中,所有 非数字型变量 都支持以下特点:
① 都是一个 序列(sequence),也可以理解为 容器
② 取值([])
③ 遍历(for in)
④ 计算长度,最大/最小值,比较,删除
⑤ 链接(+)和 重复(*)
⑥ 切片
整数类型
- 与数学中的整数概念一样,没有取值范围限制
- 一共有4种进制表示,默认十进制,其他进制需要增加引导符(不区分大小写)
- 二进制:
0b或者0B八进制:0o或者0O十六进制:0x或者0X
浮点数类型
- 浮点数类型与数学中实数的概念一样,表示带有小数的数值。必须有小数部分,小数部分可以是0
- 浮点数两种表示方式:十进制(10.0),科学计数法(1.01e3)
复数类型
- Python 语言中,复数可以看做是二元有序实数对(相当于坐标吧),
(a,b)表示a+bj,其中,a是实数部分,b是虚数部分 - z = 1.23e-4+5.6e+89j,对于复数
z,可以用z.real获取实数部分,z.imag获取虚数部分
z = 12-3j
a = z.real
b = z.imag
print(a, b) # a = 12.0 b = -3.0数字类型的运算

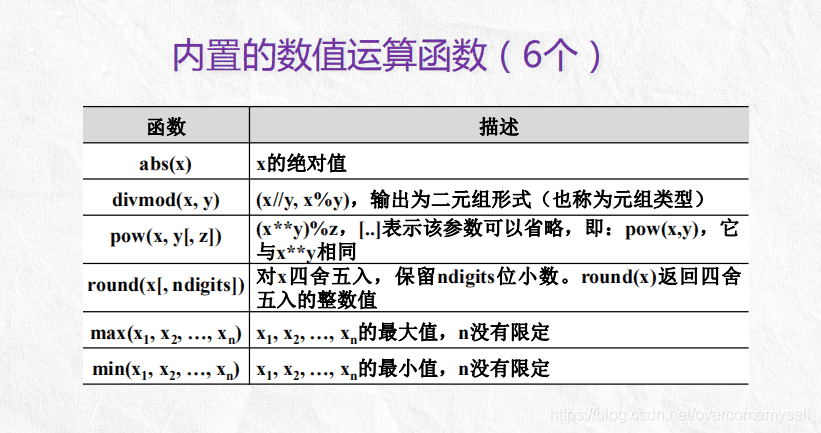
# 取商的整数部分,与浮点数运算结果也是浮点数
print(1010.0//3) # 336.0
# ** 幂运算
print(2**3) # 8
# 整数或浮点数与复数运算,结果是复数
print(10 - (1+1j)) # (9-1j)
# 绝对值
print(abs(-9)) # 9
# 把除数和余数运算结果结合起来,返回一个包含商和余数的元组
print(divmod(8, 2)) # (4,0)
# 也是幂运算
print(pow(3, 2)) # 9
# 对参数1四舍五入,参数2是保留多少位小数可省略
print(round(6.111, 2)) # 6.11
# 取最大值,没有限定多少个
print(max(1, 2, 3, 4, 5, 6, 7)) # 7
# 取最小值
print(min(1.2, -2, 0, 3)) # -2字符串类型
- 根据字符串的内容多少分为单行字符串和多行字符串
- 单行字符串由
' '或者" "括起来 - 多行字符串可以由一对三单引号
'''或者三单双引号"""括起来 - 转义字符用
\表示,例如:
\n # 表示换行
\\ # 表示反斜杠
\' # 表示单引号
\" # 表示双引号
\t # 表示Tab键
\r # 表示回车- 字符串的索引

s = "你是傻逼吗?"
print(s[0]) # 表示第0个字符- 字符串的切片(对字符串中某个子串或区间的检索)
s = "你是傻逼吗?"
# s[n:m]取值方式左到右,n从0开始,m是列表元素索引值减1
# n始终比m小(n,m可以是正数,0,负数)
# 记忆法:从列表s的第n个元素开始,取出来m-n个元素
# n和m都可以同时缺省表示输出整个字串符(m可以超出字串符数量也不会报错)
# 后面数-1开始
# 步长默认是1
print(s[0:6]) # 你是傻逼吗?
print(s[-1]) # ?- 高级用法【步长】(切片截取的内容不包含结束下标对应的数据,步长指的是隔几个下标获取一个字符)
# 每隔2个取值
print(s[1:6:2]) # 是逼?
print(s[::2]) # 你傻吗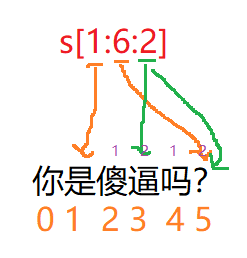
- 字符串操作符

# 连接两个字符串
s = "锄禾日当午"
s2 = "汗滴禾下土"
s3 = "锄禾日当午"
print(s+s2) # 锄禾日当午汗滴禾下土
# 复制n次字符串x
print(s*2) # 锄禾日当午锄禾日当午
# 如果x是s的子串返回True,否则返回False
print(s2 in s) # False
print(s3 in s) # True- 字符串处理函数
s = "锄禾日当午"
# 返回字符串长度
print(len(s)) # 5
# 任意类型x所对应的字符串形式
a = str(123)
print(a) # 123
# type函数返回变量的数据类型
print(type(a)) # <class 'str'>
# 整数x的十六进制或八进制小写形式字符串
num = 12345
print(hex(num)) # 0x3039
print(oct(num)) # 0o30071
# x为Unicode编码,返回其对应的ASCII字符
print(chr(65)) # A
# x为字符,返回其对应的Unicode编码
print(ord('A')) # 65- 字符串处理方法
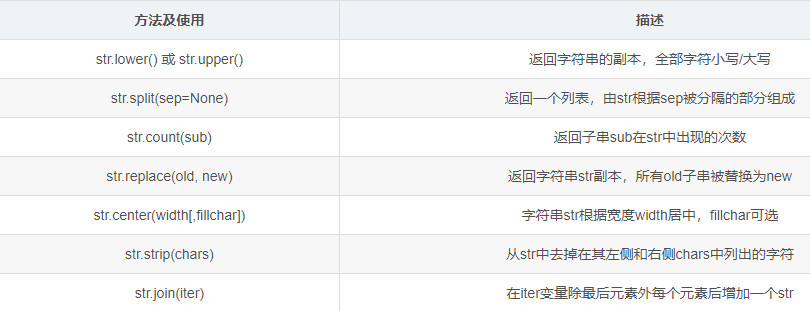
s = "aa,Bbcc,Ddf"
# 返回全部字符大写
print(s.upper()) # AA,BBCC,DDF
# 返回全部字符小写
print(s.lower()) # aa,bbcc,ddf
# 返回一个列表,由字符串被分割部分组成
# str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等
# num -- 分割次数。默认为 -1, 即分隔所有
print(s.split(',')) # ['aa','Bbcc','Ddf']
# 以哪个为分隔符,哪个分割符就不会出现在结果
print(s.split('b', 1)) # ['aa,B','cc,Ddf']
# 返回子串sub在str中出现的次数,区分大小写并且区分顺序
print(s.count("a")) # 2
print(s.count("aa")) # 0
# 返回字符串str副本,所有old字符串被替换成new
# 但对原来的字串符没影响
# 第三个参数默认-1:替换所有old出现的次数 0:不替换 1:替换出现的第一次
flag = s.replace("a", "PP")
print(s) # aa,Bbcc,Ddf
print(flag) # PPPP,Bbcc,Ddf
# 通过指定一个宽度值width,将str在该宽度内居中
# 参数二为填充的内容默认是空格填充可选,只能是单个字符
# 如果width值小于str的值则原样返回str
# 当str为奇数,指定宽度为偶数时,优先向右边补填充内容
# 当str为偶数,指定宽度为奇数时,优先向左边补填充内容
print(s.center(21, "@")) # @@@@@aa,Bbcc,Ddf@@@@@
# 从str中去掉在其左侧和右侧chars中列出的值
# 只能删除开头或是结尾的字符,不能删除中间部分的字符
# 没参数默认为空格或换⾏符
print(s.strip("af")) # ,Bbcc,Dd
# 在iter变量除最后元素外每个元素后增加一个str
s2 = '-'
s3 = ['2022', '05', '27']
print(s2.join(s3)) # 2022-05-27
print(s2.join('我还是我以前的我')) # 我-还-是-我-以-前-的-我- str.replace() 函数第三参数取值范围如下

- 字符串类型的格式化
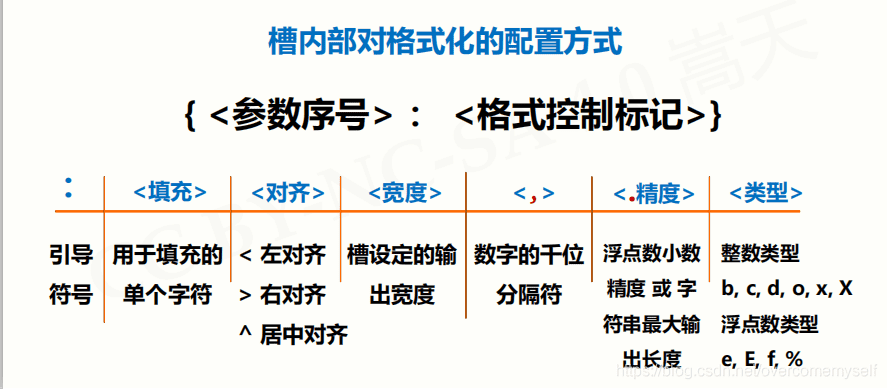
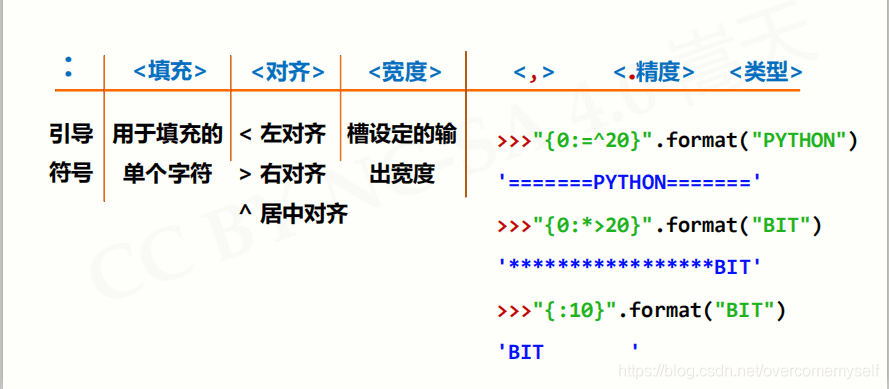
# 通过关键字(关键字= 不需要空格隔开)
print("{name}在{option}".format(name="小明", option="吃饭")) # 小明在吃饭
# 通过位置
print("{}在{}".format("小芳", "跳舞")) # 小芳在跳舞
print("{0}在{1}".format("小芳", "跳舞")) # 小芳在跳舞
print("{1}在{0}".format("小芳", "跳舞")) # 跳舞在小芳
# 居中
# 20:字段长度(最左到最右之间的长度)
print("{:=^20}".format("123")) # ========123=========
# 左对齐
print("{:<20}".format("123"))
# 右对齐
print("{:>20}".format("123"))
# 精度控制(保留2位小数并且四舍五入)
print("{:.2f}".format(3.14859)) # 3.15
# 进制转换 b o d x 分别表示二、八、十、十六进制
print("{:b}".format(29)) # 11101
print("{:o}".format(29)) # 35
print("{:d}".format(29)) # 29
print("{:x}".format(29)) # 1d
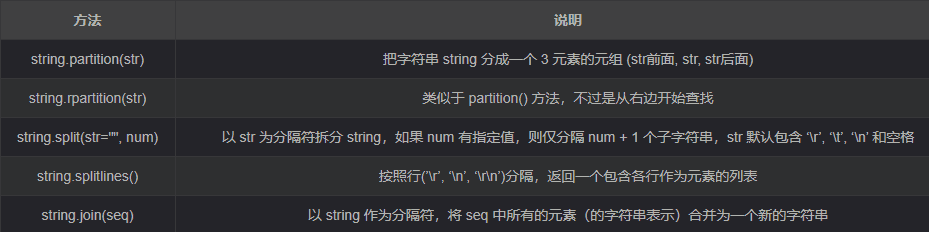
附录1 字符串常用操作
- 判断类型
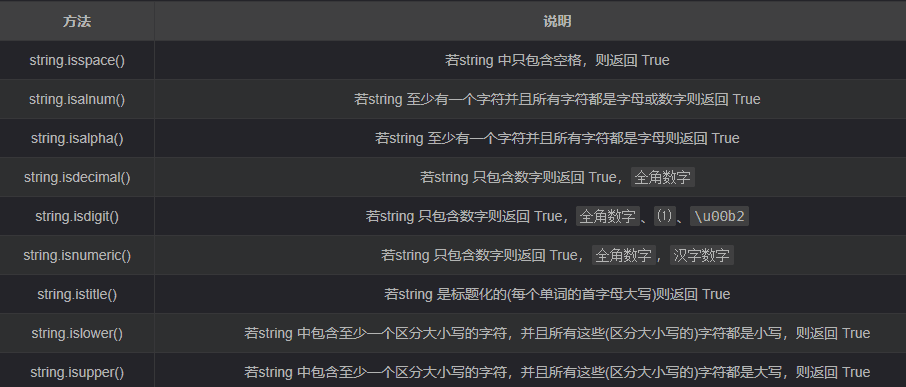
- 查找和替换
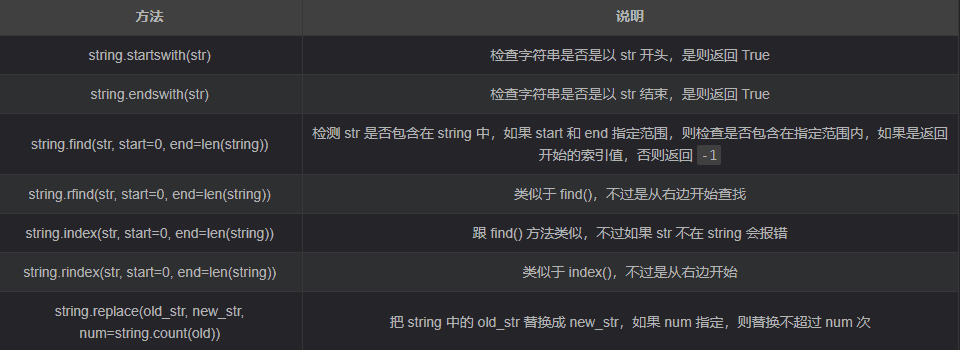
- 大小写转换
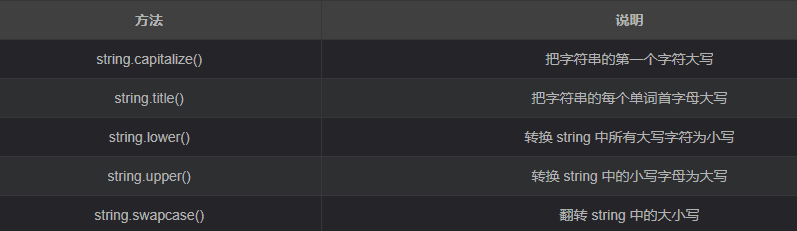
- 文本对齐

- 去除空白字符
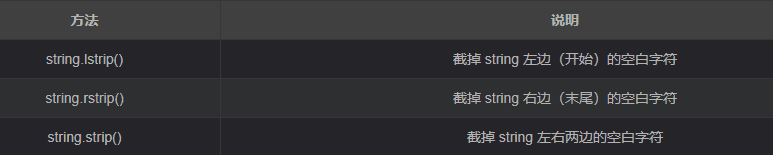
- 拆分和连接
数据类型之序列类型
定义
- 序列是具有先后关系的一组元素
- 序列是一维元素向量,元素类型可以不同
- 元素间由序号引导,通过下标访问序列的特定元素
- Python语言中很多数据类型都是序列类型,其中比较重要的是字符串类型,元组类型和列表类型。
通用操作符与函数
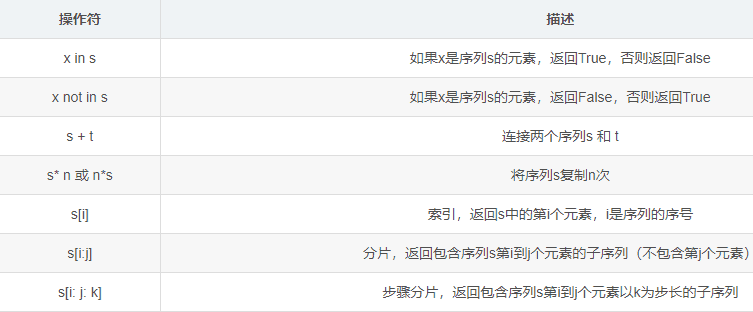
arr = ["python", "C语言", "1223"]
brr = ["MySQL", "挂科"]
# 如果x是序列arr的元素返回True,否则返回false
print("C语言" in arr) # True
print("C语" in arr) # False
# 如果x是序列arr的元素,返回False,否则返回True
print("python" not in arr) # False
print("sb" not in arr) # True
# 连接两个序列arr和brr
print(arr+brr) # ['python', 'C语言', '1223', 'MySQL', '挂科']
# 将序列arr复制n次
print(arr*2) # ['python', 'C语言', '1223', 'python', 'C语言', '1223']
# 索引,返回arr中第i个元素
print(arr[0]) # python
# 切片,返回序列arr第i到第j个元素(不包括第j个元素)
# 跟字符串操作一样
print(arr[1:3]) # ['C语言', '1223']
# 切片,返回序列arr第i到第j个元素(不包括第j个元素),以k为步长
print(arr[0:3:2]) # ['python', '1223']
print(arr[::-1]) # ['1223', 'C语言', 'python']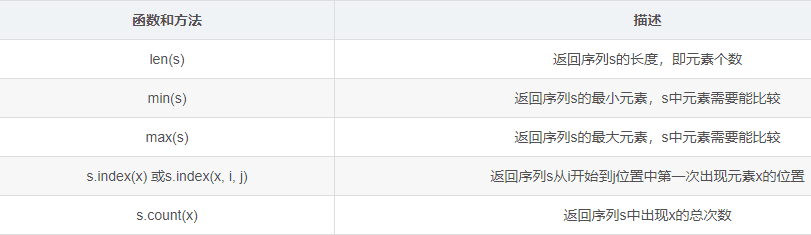
arr = ["python", "C语言", "A"]
brr = ["12", "12", "12", "23"]
# 返回序列arr的长度,即元素个数
print(len(arr)) # 3
# 返回序列arrASCII码最小的元素,arr中元素需要能比较
print(min(arr)) # A
# 返回序列arrASCII最大元素
print(max(arr)) # python
# 返回序列arr从i到j第一次出现元素x的位置
# 如果i到j都没有这个元素则报错
print(arr.index("python")) # 0
print(arr.index("A", 0, 3)) # 2
# 返回序列arr中出现x的总次数
print(brr.count("12")) # 3数据类型之列表类型
定义
List(列表) 是Python中使用 最频繁 的数据类型,在其他语言中通常叫做 数组- 专门用于存储 一串 信息
- 列表用
[]定义,数据 之间使用,分隔 - 列表中各元素类型可以不同,无长度限制
- 列表的索引从0开始
注意:从列表中取值时,如果 超出索引范围,程序会报错
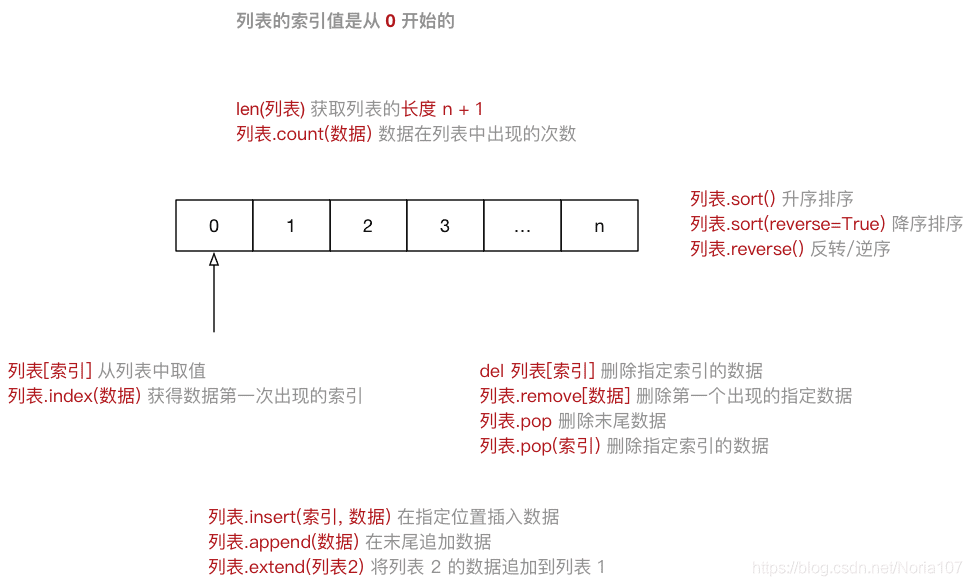
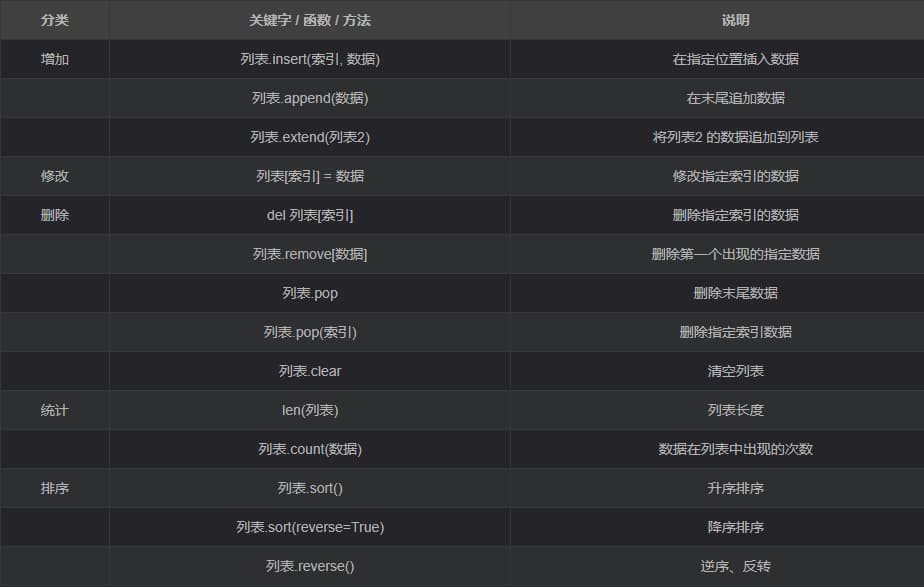
# 创建列表
list1 = [1, 2, 3, 4, 5]
list2 = ["C语言", "C++"]
# 在指定位置插入数据
list1.insert(0, 0)
print(list1) # [0, 1, 2, 3, 4, 5]
# 在末尾追加数据
list1.append(6)
print(list1) # [0, 1, 2, 3, 4, 5, 6]
# 将list2的数据追加到list1
list1.extend(list2)
print(list1) # [0, 1, 2, 3, 4, 5, 6, 'C语言', 'C++']
# 修改指定索引数据
list1[0] = -1
print(list1) # [-1, 1, 2, 3, 4, 5, 6, 'C语言', 'C++']
# 删除指定索引的数据
del list1[8]
print(list1) # [-1, 1, 2, 3, 4, 5, 6, 'C语言']
# 删除第一个出现的指定数据
list1.remove(1)
print(list1) # [-1, 2, 3, 4, 5, 6, 'C语言']
# 删除末尾数据
list1.pop()
print(list1) # [-1, 2, 3, 4, 5, 6]
# 删除指定索引数据
list1.pop(5)
print(list1) # [-1, 2, 3, 4, 5]
# 列表长度
print(len(list1)) # 5
# 数据在列表中出现的次数
print(list1.count(2)) # 1
# 升序排序,没参数默认升序
list1.sort()
print(list1) # [-1, 2, 3, 4, 5]
# 降序
list1.sort(reverse=True)
print(list1) # [5, 4, 3, 2, -1]
# 逆序
list1.reverse()
print(list1) # [-1, 2, 3, 4, 5]
# 复制列表,生成新的列表
list3 = list1.copy()
print(list3) # [-1, 2, 3, 4, 5]
# 清空列表
list1.clear()
print(list1) # []- 迭代遍历
list1 = [1, 2, 3, 4, 5]
# 遍历
for name in list1:
print(name)数据类型之元组类型
定义
- 元组是序列类型的一种扩展
- 一旦创建就不能被修改
- 使用小括号 () 或 tuple() 创建,元素间用逗号分隔(字符串元素用单引号或者双引号括起来,数值则不需要)
- 可以使用或不使用小括号
- 索引也是从0开始
- 元组是不可变类型,它的指针数组无需变动,故内存分配乃一次性完成。另外,系统会缓存复用一定长度的元组内存。创建时,按长度提取复用,无需额外内存分配(包括指针数组)。从这点上看,元组的性能要好于列表。
- 元组可当做列表的只读版本使用
- 元组相同序号总是返回同一对象,故可为序号取个别名
注意:元组中 只包含一个元素 时,需要 在元素后面添加逗号
tuple1 = (12,)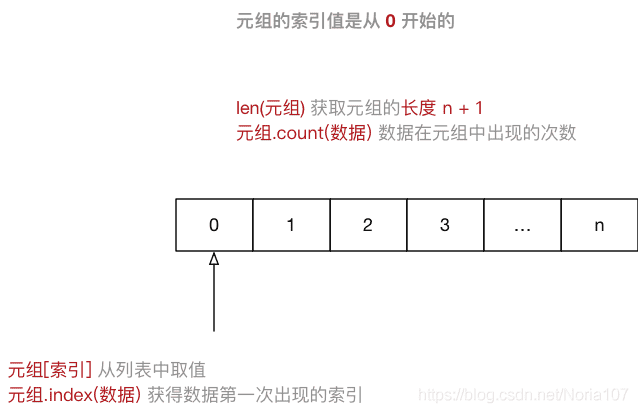
常用操作
元组继承了序列类型的全部通用操作,但是由于创建后不能修改,因此没有特殊操作
# 创建空元组
tuple1 = ()
# 可以不使用小括号
tuple2 = 12, 13, 14, 15
tuple3 = ("abc", "def")
print(tuple2) # (12, 13, 14, 15)
# 访问元组
print(tuple2[2]) # 14
# 倒序
print(tuple2[::-1]) # (15, 14, 13, 12)
# 元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
tuple4 = tuple2 + tuple3
print(tuple4) # (12, 13, 14, 15, 'abc', 'def')
print(type(tuple4)) # <class 'tuple'>
# 元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组
del tuple4
print("删除后:\n")
print(tuple4) # 报错:未定义'tuple4'
# 计算元素个数
print(len(tuple2)) # 4
# 复制
print(tuple2*2) # (12, 13, 14, 15, 12, 13, 14, 15)
# 元素是否存在
print(12 in tuple2) # True
# 遍历
for my_tuple in tuple2:
print(my_tuple) # 12 13 14 15应用场景
- 尽管可以使用
for in遍历 元组 - 在开发中应用场景是:
① 函数的 参数 和 返回值,一个函数可以接收 任意多个参数,或者 一次返回多个数据
② 格式字符串,格式化字符串后面的()本质上就是一个元组
③ 让列表不可以被修改,以保护数据安全
info = ("小明", 18)
print("%s的年龄是%d" % info) # 小明的年龄是18元组和列表之间的转换
- 使用
list函数可以把元组转换成列表
list(元组)- 使用
tuple函数可以把列表转换成元组
tuple(列表)数据类型之字典类型
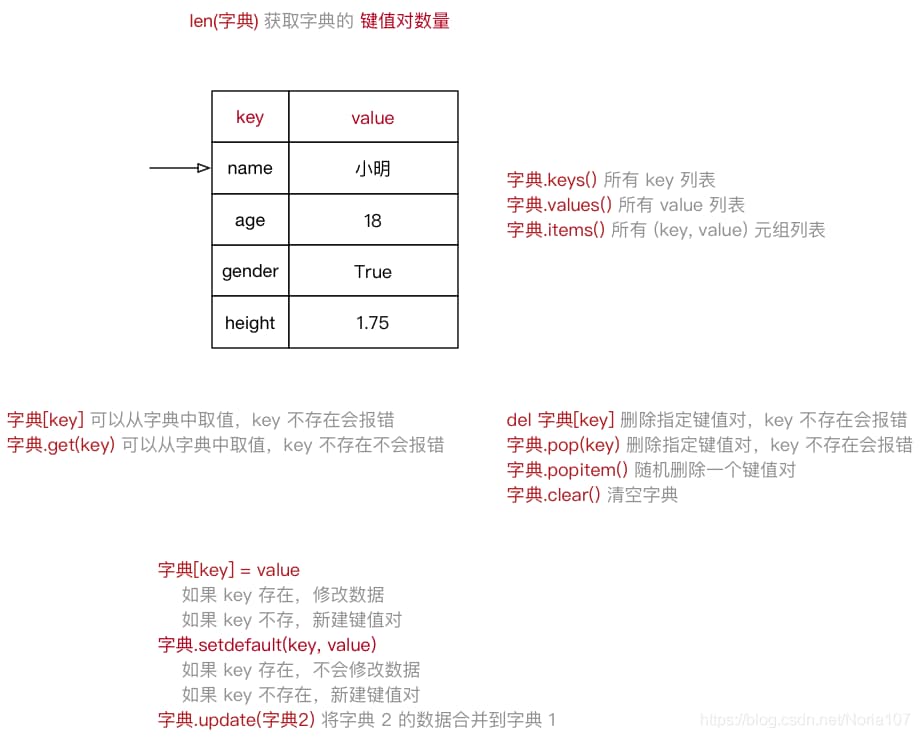
定义
dictionary(字典) 是 除列表以外Python之中 最灵活 的数据类型(类似C语言的结构体)- 字典同样可以用来 存储多个数据(通常用于存储 描述一个
物体的相关信息) - 和列表的区别
列表 是 有序 的对象集合
字典 是 无序 的对象集合 - 字典用
{}定义
字典使用 键值对 存储数据,键值对之间使用,分隔 - 键
key是索引 值value是数据 - 键 和 值 之间使用
:分隔 键必须是唯一的
值 可以取任何数据类型,但 键 只能使用 字符串、数字或 元组(列表不行) - 字典是包含0个或多个键值对的集合,没有长度限制,可以根据键索引值的内容
# 定义一个字典
# 使用字典来存储用户提供的数据或在编写能自动生成大量键-值对的代码时,都通常需要先定义一个空字典
dict1 = {"name": "小红", "年龄": 19, "电话": 123456}
print(type(dict1)) # <class 'dict'>
# 返回所有key(键)
# 返回所有value(值)
print(dict1.keys()) # dict_keys(['name', '年龄', '电话'])
print(dict1.values()) # dict_values(['小红', 19, 123456])
# 返回(key, value)元组列表
print(dict1.items()) # dict_items([('name', '小红'), ('年龄', 19), ('电话', 123456)])
# 取值,key不存在会报错(注意要加引号)
print(dict1["name"]) # 小红
# 取值,key不存在不会报错,会返回default值:None
print(dict1.get("na")) # None
# 如果key存在,修改数据,不存在则新建键值对
dict1["生日"] = 20020829
print(dict1) # {'name': '小红', '年龄': 19, '电话': 123456, '生日': 20020829}
dict1["name"] = "李四"
print(dict1["name"]) # 李四
# 如果key存在,不会修改数据,不存在则新建
dict1.setdefault("name", "小虎")
print(dict1) # {'name': '李四', '年龄': 19, '电话': 123456, '生日': 20020829}
dict1.setdefault("height", "1.75")
print(dict1) # {'name': '李四', '年龄': 19, '电话': 123456, '生日': 20020829, 'height': '1.75'}
# 将dict2的数据合并到dict1中
dict2 = {"学号": 2021}
dict3 = dict1.update(dict2) # 不能赋值,这是错误的
print(dict1) # {'name': '李四', '年龄': 19, '电话': 123456, '生日': 20020829, 'height': '1.75', '学号': 2021}
# 删除指定键值对,key不存在会报错(两种方法)
dict1.pop('电话')
print(dict1) # {'name': '李四', '年龄': 19, '生日': 20020829, 'height': '1.75', '学号': 2021}
del dict1["生日"]
print(dict1) # {'name': '李四', '年龄': 19, 'height': '1.75', '学号': 2021}
# 随机删除一个键值对(一般删除末尾对)
dict1.popitem()
print(dict1) # {'name': '李四', '年龄': 19, 'height': '1.75'}
# 返回字典的键值对数
print(len(dict1)) # 3
# 判断键是否在字典dict1中,如果在返回True,否则False
print("name" in dict1) # True
# 清空字典
dict1.clear()
print(dict1) # {}- 遍历字典(可遍历字典的所有键值对、键或值)
# 遍历所有键值对
dict1 = {"name": "小红", "年龄": 19, "电话": 123456}
for name in dict1:
print("%s: %s" % (name, dict1[name]))
# 需要字典的值都是字符串类型,否则报错
dict1 = {"name": "小红", "年龄": "19", "电话": "123456"}
for key, value in dict1.items():
print("\nkey:" + key)
print("value:" + value)
# 输出所有的键
dict1 = {"name": "小红", "年龄": "19", "电话": "123456"}
for key in dict1.keys():
print(key)
# 或者
dict1 = {"name": "小红", "年龄": "19", "电话": "123456"}
for name in dict1:
print(name)
# 输出所有的值
dict1 = {"name": "小红", "年龄": "19", "电话": "123456"}
for value in dict1.values():
print(value)
# sorted默认时是对键进行排序
dict1 = {"A": "2", "C": "5", "B": "1"}
# 键排序
for name in sorted(dict1):
print(name)
# 值排序(降序)
for name in sorted(dict1.values(), reverse=True):
print(name)
- 为剔除重复项,可以使用集合
(set)。集合类似于列表,但对每个元素都必须是独一无二的。通过对包含重复元素的列表调用set(),可以让Python找出列表中独一无二的元素,并使用这些元素来创建集合
dict1 = {"A": "2", "C": "2", "B": "1", "F": "2"}
# 值去重
for name in set(dict1.values()):
print(name)
数据类型之集合类型
定义
- 集合是多个元素的无序组合
- 集合元素之间无序,每个元素唯一,不存在相同元素(应用于数据去重,即集合类型所有元素无重复)
- 集合元素不可更改,不能是可变数据类型
- 集合用大括号
{}表示,元素间用,分隔 - 建立集合类型用
{}或set() - 建立空集合类型,必须使用
set()
gather = {123, "123", "A", "BB"}
gather2 = {123, "金", "木"}
# 返回类型
print(type(gather)) # <class 'set'>
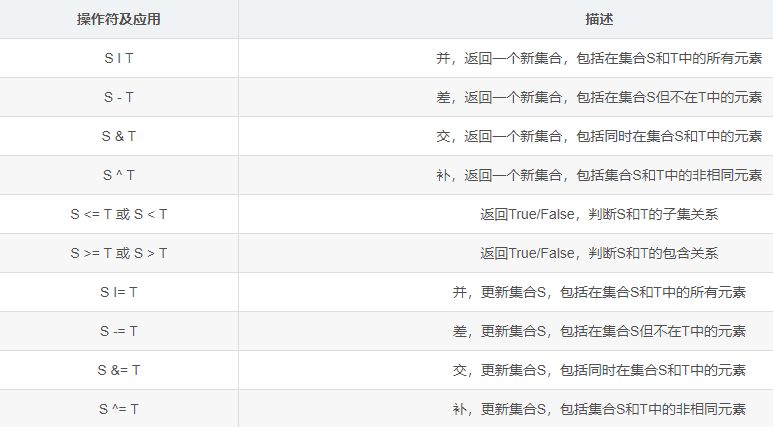
# S|T,返回所有元素的新集合
gather3 = gather | gather2
print(gather3) # {'BB', '金', '木', 'A', 123, '123'}
# S&T,返回两个集合相同的元素
gather3 = gather & gather2
print(gather3) # {123}
# S-T,返回包括在集合S但不在T中的元素
gather3 = gather - gather2
print(gather3) # {'A', '123', 'BB'}
# S^T,返回包括集合S和T中的非相同的元素
gather3 = gather ^ gather2
print(gather3) # {'A', '123', 'BB', '金', '木'}
# S<=T或S<T,返回True/False,判断两个集合的子集关系
# 如果集合S的元素都属于集合T的元素,那说明T包含S,T<=S(两个集合元素一样需要<=/==)
gather4 = {123}
gather3 = gather <= gather2
print(gather3) # False
gather3 = gather4 <= gather # 等同于 gather >= gather4
print(gather3) # True
# S|=T,并,更新集合S,跟上面那个一样(这个不会生成新集合)
gather |= gather2
print(gather) # {'木', 'BB', 'A', 123, '金', '123'}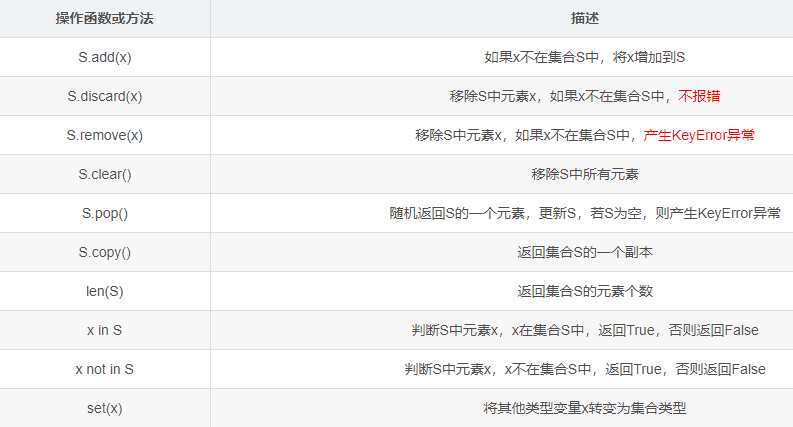
gather = {123, "123", "A", "BB"}
# 如果x不在集合S中,将x增加到S
gather.add(666)
print(gather) # {'A', '123', 666, 123, 'BB'}
# discard:移除S中元素x,如果x不在集合S中,不报错
# remove:移除S中元素x,如果x不在集合S中,产生KeyError异常
gather.discard(123)
print(gather) # {'A', 'BB', '123', 666}
# gather.remove(0)
# print(gather) # KeyError: 0
# 随机删除S的一个元素,更新S,若S为空,则产生KeyError异常
gather.pop()
print(gather) # {'BB', 666, '123'}
# 返回集合S的一个副本
gather2 = gather.copy()
print(gather2) # {'BB', 666, '123'}
print(len(gather)) # 3
# 判断S中元素x,x在集合S中,返回True,否则返回False
print(123 in gather) # False
# 判断S中元素x,x不在集合S中,返回True,否则返回False
print(123 not in gather) # True
# 将其他类型变量x转变为集合类型(去重)
tuple1 = (1, 2, 1, 3, 6)
print(set(tuple1)) # {1, 2, 3, 6}控制语句
分支结构与选择结构
Python程序语言指定任何非0和非空(null)值为true,0 或者 null为falsePython是⼀种靠缩进来判断逻辑的语言!所以缩进尤为重要,如果缺失缩进程序运行会报错!Python采用代码缩进和冒号( : )来区分代码块之间的层次- 对于类定义、函数定义、流程控制语句、异常处理语句等,行尾的冒号和下一行的缩进,表示下一个代码块的开始,而缩进的结束则表示此代码块的结束
- 通常情况下都是采用 4 个空格长度作为一个缩进量(默认情况下,一个 Tab 键就表示 4 个空格)
Python要求属于同一作用域中的各行代码,它们的缩进量必须一致,但具体缩进量为多少,并不做硬性规定
# 注意缩进
if 2 > 1:
print("true")
print("True")
# 运行结果:true True
a = 2
if a == 0: # 注意不能直接2==0
print("你好")
else:
print("不好")
# 运行结果:不好
# 紧凑形式
# <表达式1> if <条件> else <表达式2>
# 条件成立则输出表达式1,不成立则输出表达式2
guess = eval(input("请输入数字:"))
print("你猜{}了".format("对" if guess == 99 else "错")) # 99 你猜对了
a = 1
b = 2
# and:与 or:或 not:非
if (a and b) > 0:
print("大于0")
else:
print("小于0")
# 输出结果:大于0a = 1
b = 2
# 从上到下运行
if (a and b) > 0:
print("第一")
elif a == 1:
print("第二")
elif b == 2:
print("第三")
else:
print("第四")
# 输出结果:第一# 嵌套
a = 1
b = 2
if (a and b) > 0:
if a == 1:
print("666")
else:
print("999")
else:
print("123")
# 输出结果:666注意:elif 和 else 都必须和 if 联合使用,不能单独使用,虽然该语句的备选动作较多,但是有且只有一组动作被执行
- pass语句
Python 提供了一个关键字 pass,类似于空语句,可以用在类和函数的定义中或者选择结构中。当暂时没有确定如何实现功能,或者为以后的软件升级预留空间,都可以使用该关键字来“占位”。
a = 1
b = 2
if (a and b) > 0:
pass
else:
pass
# 输出结果:无- 随机数的处理
# 导入模块
import random
num1 = random.randint(1, 10) # 生成随机数n:1<=n<=10
num2 = random.randint(3, 3) # 结果永远是3
num3 = random.randint(10, 3) # 错误,下限必须小于上限循环结构
- while 循环
a = 1
while a < 20:
print(a)
a += 5
# 输出结果:1 6 11 16# while … else 在循环条件为 false 时执行 else 语句块
# 循环正常执行完才会执行else,break导致退出的不会执行
a = 1
while a < 4:
print(a)
a += 1
else:
print(666)
# 输出结果:1 2 3 666
# 如果你的 while 循环体中只有一条语句,你可以将该语句与while写在同一行中
while 1: print(6)- for循环
# 从遍历结构中逐一提取元素,放在循环变量中
# 每次循环,所获得元素放入循环变量,并执行一次语句块
for<循环变量> in <遍历结构>:
<语句块>- range(start, stop[, step]) 函数可创建一个对象(Python3),参数1:计数开始处,默认
0;参数2:结束处,不包括参数2本身;参数3:步长,默认1
str1 = "123456"
for i in range(len(str1)):
print(str1[i]) # 1 2 3 4 5 6
# 0-3,步长为2
# for ... else 跟 while ... else 一样
num = 0
for i in range(0, 4, 2):
print(num+i)
else:
print("正常结束")
# 输出结果:# 0 2 正常结束
# 列表循环遍历
for i in ["1", "2", "3"]:
print(i) # 1 2 3
# 文件遍历循环
# fi是一个文件标识符,遍历每行产生循环
for line in fi
<语句块>循环控制保留字
- break 语句
break用来跳出最内层for或while循环,脱离该循环后程序从循环代码后继续执行
注意:若有双重循环时,仅退出当前层次循环
s1 = "abcde"
for name in s1:
if name == "c": # 遇到c直接退出循环
break
print(name) # a b - continue语句
用来结束当前当次循环,即跳出循环体中下面尚未执行的语句,但不跳出当前循环
s1 = "abcde"
for name in s1:
if name == "c": # 跳过c
continue
print(name) # a b d e注意:break 和 continue 只针对 当前所在循环 有效
try-except语句
- 这个
try-except语句是异常捕获语句 - eval() 函数用来执行一个字符串的表达式,并返回表达式的值
- 还可以把字符串转化为list、tuple、dict
s1 = "[1, 2, 3, 4, 5]"
print(type(s1)) # <class 'str'>
s2 = eval(s1)
print(type(s2)) # <class 'list'>
# 主要看" "里面是什么类型就转换成什么类型
# []->列表 {}->字典 ()->元组
# 还可以返回表达式的值
a = 4
print(eval("a+1")) # 5
x=10
b=20
c=30
g={'a':6,'b':8} # a=6 b=8
t={'b':100,'c':10} # b=100 c=10
eval('a+b+c',g,t) # 优先使用局部变量所以上面的x,b,c不会用到,然后按顺序执行,把g,t位置调换结果也会不同
# 返回值为116- 异常处理
# 语法
try: # # 写一个 try 把可能出错的代码放进去
<语句块1>
except <异常类型>: # 写一个except
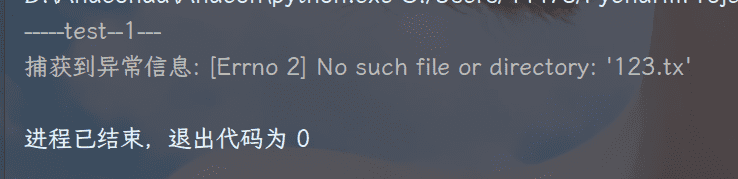
<语句块2> # 书写捕获异常的处理方案try:
print("-----test--1----")
open("123.txt", "r")
print("-----test--2--- ")
except IOError as e:
print("捕获异常", e)
# 捕获到异常,没有这个123.txt文件
# 运行结果:
# -----test--1----
# 捕获异常 [Errno 2] No such file or directory: '123.txt'① 此程序捕获到错误,因为用 except 捕获到了 IOError 异常,并添加了处理的方法
② except 添加错误基类 IOError try语句出错则执行 except 下print语句,那么就会输出错误信息
③ 从执行结果可以看到:捕获到的错误保存到变量,控制台可以打印出具体的错误信息。
try:
print(num)
except IOError:
print("捕获异常")运行结果:

注意:except 捕获的错误类型是 IOError ,而此时程序产生的异常为 NameError ,所以 except 没有生效
- 当捕获多个异常时,可以把要捕获的异常的名字,放到
except后,并使用元组的方式仅进行存储
try:
print('-----test--1---')
open('123.tx','r') # 如果123.txt文件不存在,那么会产生 IOError 异常
print('-----test--2---')
print(num)# 如果num变量没有定义,那么会产生 NameError 异常
except (IOError,NameError) as e:
# 如果想通过一次except捕获到多个异常可以用一个元组的方式
print('捕获到异常信息:',e)
-
此处的
else语句与for循环和while循环中else一样,当try中的语句块1正常执行结束且没有发生异常时,else中的语句块3执行。2、
finall语句块则不一样,无论try中的语句块1是否发生异常,语句块4都会执行,因此将程序执行语句块1的一些收尾工作放在这里,例如:关闭、打开文件等。
try:
<语句块1>
except<异常类型1>:
<语句块2>
else:
<语句块3>
finally:
<语句块4>- 当你不知道错误基类时,就统一用
Exception(可以捕获所有错误)
函数的定义与使用
函数的定义
def是英文define的缩写- 函数命名应该符合 标识符的命名规则

-
函数调用:通过
函数名()即可对函数调用,定义完成后,若不自动调用函数,函数不会自动执行 -
在函数名后面的小括号内部填写 参数,参数之间用
,分隔 -
形参和实参:
① 形参:定义函数时,小括号中的参数,用于接收参数,在函数内部 作为变量使用
② 实参:调用 函数时,小括号中的参数,将数据传递到 函数内部
-
return表示返回,后续的代码都不会被执行
lambda 函数
lambda 表达式可以用来声明匿名函数,又称 lambda函数 ,匿名函数不是真的没有名字,而是将函数名作为函数结果返回
<函数名> = lambda <参数列表>: <表达式>
# 等价于下面形式
def <函数名>(<参数列表>):
return <表达式># 将lambda 函数赋给一个变量
num = lambda x, y: x+y
print(type(num)) # <class 'function'>
print(num(1, 2)) # 3
# 警告:PEP 8:E731 do not assign a lambda expression,use a def
# PEP8规范并不推荐将lambda表达式赋值给一个变量,再通过变量调用函数这种方式。
# 这种方式不能体现lambda表达式的特色,基本只是复制def的功能,
# 同时这个变量名其实也不是lambda表达式真正的函数名,还显得比def方式更容易混淆- 写完函数和类之后要空出两个空行(方便区分)
- 如果定义的函数没有返回值,
Python解释器就会(强行地)默认给我们注入一段返回逻辑!(None) - return语句同时可以将0个、1个或多个函数运算完的结果返回给函数被调用处的变量,返回多个值时以元组类型保存
- 如果一个函数返回的是元组,括号可以省略
# 函数可以没参数,但是括号必须保留
def fact():
print("这是个函数")
def fact2(x, y):
return x+y
print(fact()) # 这是个函数 None
print(fact2(2, 4)) # 6参数
- 定义函数时,给某个参数指定一个默认值,叫做
缺省 - 调用函数时,如果没有传入参数则默认使用
默认参数
注意:必须保证带有默认值的缺省参数在参数列表末尾,在调用函数时,如果有多个缺省参数,需要指定参数名,这样解释器才能够知道参数的对应关系!

def fact2(x=1, y=2):
return x+y
# 指定参数名,不指定默认是替换左边
print(fact2(y=9)) # 10使用模块中的函数
- 模块 就好比是 工具包,要想使用这个工具包中的工具,就需要 导入 import 这个模块
- 每一个以扩展名
py结尾的Python源代码文件都是一个 模块 - 在模块中定义的 全局变量 、 函数 都是模块能够提供给外界直接使用的工具
- 可以 在一个 Python 文件 中 定义 变量 或者 函数,然后在 另外一个文件中 使用
import导入这个模块 - 导入之后,就可以使用
模块名.变量/模块名.函数的方式,使用这个模块中定义的变量或者函数 - 模块名也是遵循标志符起名规则
不可变和可变参数
- 在
Python中,string(字符串),tuples(元组), 和number(数值)是不可更改的对象(形参),而list(列表),dict(字典)等则是可以修改的对象(实参) Python中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象- 形参的数值对于外部的实参的数值(number类型,不可变)来说是没有任何关系的,他们虽然是同一个名字,但是其指向对象是不一样的
x = 1
y = 2
def fact2(x, y):
x = 3
y = 6
return x+y
fact2(x, y)
print(x, y) # 1 2
# 修改实参
def change(list1):
list1.append(6)
print(list1) # [1, 2, 3, 6]
my_list = [1, 2, 3]
change(my_list)
print(my_list) # [1, 2, 3, 6]
多值参数
-
有时可能需要 一个函数 能够处理的参数 个数 是不确定的,这个时候,就可以使用 多值参数
-
python中有两种多值参数:
① 参数名前增加 一个
*可以接收 元组 如:*args② 参数名前增加 两个
*可以接收 字典 如:**kwargs
def power(*tuple1):
result = 0
for n in tuple1:
result += n
return result
my_tuple = (1, 3, 5, 7)
print(power(*my_tuple)) # 16
def power(name, age, **dict1):
print("name:", name, "age:", age, "other:", dict1 )
my_dict = {"A": 1, "B": 2, "C": 3}
power("Jack", 18, **my_dict)
# 运行结果:name: Jack age: 18 other: {'A': 1, 'B': 2, 'C': 3}
# 注意:要两个*才代表字典,一个*是元组- 可变参数既可以直接传入:func(1, 2, 3),又可以先组装
list或tuple,再通过*args传入:func(*(1, 2, 3)) - 关键字参数既可以直接传入:func(a=1, b=2),又可以先组装
dict,再通过**kw传入:func(**{‘a’: 1, ‘b’: 2})
def power(*dict1):
print("other:", dict1)
power(*(1, 2, 3, 4))
# 运行结果:other: (1, 2, 3, 4)递归的关键特征
- 存在一个或多个基例,基例不需要再次递归,它是确定的表达式(是一个能直接算出值的表达式)。
- 所有递归链要以一个或多个基例结尾
Python的递归深度是有限制的,默认为1000。当递归深度超过1000时,就会报错
字符串倒序:
def reverse(s):
if s == "":
return s
else:
return reverse(s[1:]) + s[0]
arr = input("请输入一个字符串:")
print(reverse(arr))
# 或者
print(arr[::-1])# 斐波那契数列
def f(n):
if n == 1 or n == 2 :
return 1
else:
return f(n-1) + f(n-2)
n = eval(input("请输入一个整数:"))
x = f(n)
print(x)一维数据与二维数据
一维数据
-
一维数据的表示:列表类型可以表达一维有序数据,集合类型可以表达一维无序数据
-
for循环可以遍历数据,进而对每个数据进行处理 -
一维数据的存储
① 存储方式一:空格分隔
使用
一个或多个空格分隔进行存储,不换行② 存储方式二:逗号分隔
使用
英文半角逗号分隔数据进行存储,不换行③ 存储方式三:其他方式
使用
其他符号或符号组合分隔,建议采用特殊符号 -
一维数据的写入处理
① 采用空格分隔方式将数据写入文件:
Is = ["李白", "张飞", "周瑜", "孙尚香", "孙悟空"]
tf = open("E:\\测试.txt", "w")
tf.write(" ".join(Is))
tf.close()
② 采用特殊符号分隔方式将数据写入文件:
Is = ["李白", "张飞", "周瑜", "孙尚香", "孙悟空"]
tf = open("E:\\测试.txt", "w")
tf.write("@".join(Is))
tf.close()
-
一维数据的读入处理
① 从空格分隔的文件中读入数据:
tf = open("E:\\测试.txt", "r", encoding="gb2312")
txt = tf.read()
Is = txt.split() # 如果屏蔽此句则原样输出
print(Is)
tf.close()
# 输出为列表形式
# 运行结果:['李白', '张飞', '周瑜', '孙尚香', '孙悟空']注意:如果报错:UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xc0 in position 0: invalid start byte ; 则需要把 utf-8 改成 gb2312
② 从特殊符号分隔的文件中读入数据:
tf = open("E:\\测试.txt", "r", encoding='gb2312')
txt = tf.read()
Is = txt.split("@")
print(Is)
tf.close()
# 运行结果:['李白', '张飞', '周瑜', '孙尚香', '孙悟空']二维数据
- 列表类型可以表达二维数据(使用二维列表)
- 使用
两层for循环遍历每个元素 CSV格式与二维数据存储
注意:每行一个一维数据,采用 , 分隔,无空行
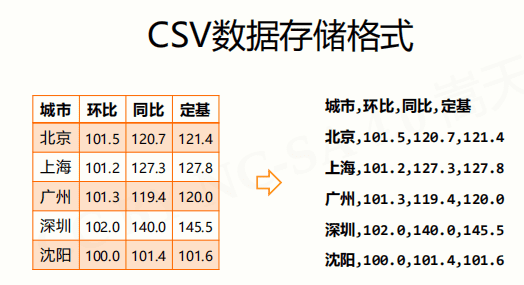
注意:
① 纯文本格式,通过单一编码表示字符。
② 以行为单位,开头不留空行,行之间没有空行
③ 每行表示一个一维数据,多行表示二维数据。
④ 以逗号(英文,半角)分割每列数据,列数据为空也要保留逗号
⑤ 对于表格数据,可以包含或不包含列名,包含时列名放置在文件第一行。
① 二维数据的写入处理(将数据写入CSV格式的文件)
# 方法1
import csv # 导入模块
Is = [["姓名", "数学", "英语"], ["小虎", "56", "87"], ["小兰", "76", "89"]]
# 表示写入csv文件,如果不加上参数 newline='' 表示以空格作为换行符不加会出现一行隔一行
tf = open("E:\\测试.csv", "w", newline="")
writer = csv.writer(tf)
for name in Is:
writer.writerow(name) # 将多列数据写入一行
tf.close()# 方法2
Is = [["姓名", "数学", "英语"], ["小虎", "56", "87"], ["小兰", "76", "89"]]
tf = open("E:\\测试.csv", "w")
for name in Is:
tf.write(",".join(name) + "\n") # 列表item以“,”为分隔符转换成字符串写入
tf.close()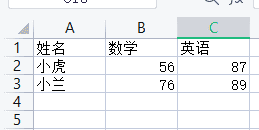
② 二维数据的读入处理(从CSV格式的文件中读入数据)
# 方法1
tf = open("E:\\测试.csv", "r")
Is = [] # 建一个空白列表
for name in tf:
name = name.replace("\n", " ") # 把换行换成空格
Is.append(name.split(","))
print(Is) # 此时Is为二维数据,所以应注意输出格式
for name in Is:
name = ",".join(name) # 列表以“,”为分隔符转换成字符串传输出
print(name)
tf.close()# 方法2
import csv
tf = open("E:\\测试.csv", "r")
reader = csv.reader(tf)
# 因为csv.reader()返回是一个迭代类型,需要通过循环或迭代器访问
# 所以你需要自己开一个列表,循环这个reader将内容添加至新的列表中即可
print(reader) # <_csv.reader object at 0x0000023F6D36F340>
show = []
for i in reader:
show.append(i)
print(show) # # 此时Is为二维数据,所以应注意输出格式
for i in show:
print(i)